mirror of
https://github.com/oceanprotocol/docs.git
synced 2024-11-01 07:45:40 +01:00
4.2 KiB
4.2 KiB
| title | section | description |
|---|---|---|
| Compute Workflow | developers | Understanding the Compute-to-Data (C2D) Workflow |
🚀 Now that we've introduced the key actors and provided an overview of the process, it's time to delve into the nitty-gritty of the compute workflow. We'll dissect each step, examining the inner workings of Compute-to-Data (C2D). From data selection to secure computations, we'll leave no stone unturned in this exploration.
For visual clarity, here's an image of the workflow in action! 🖼️✨
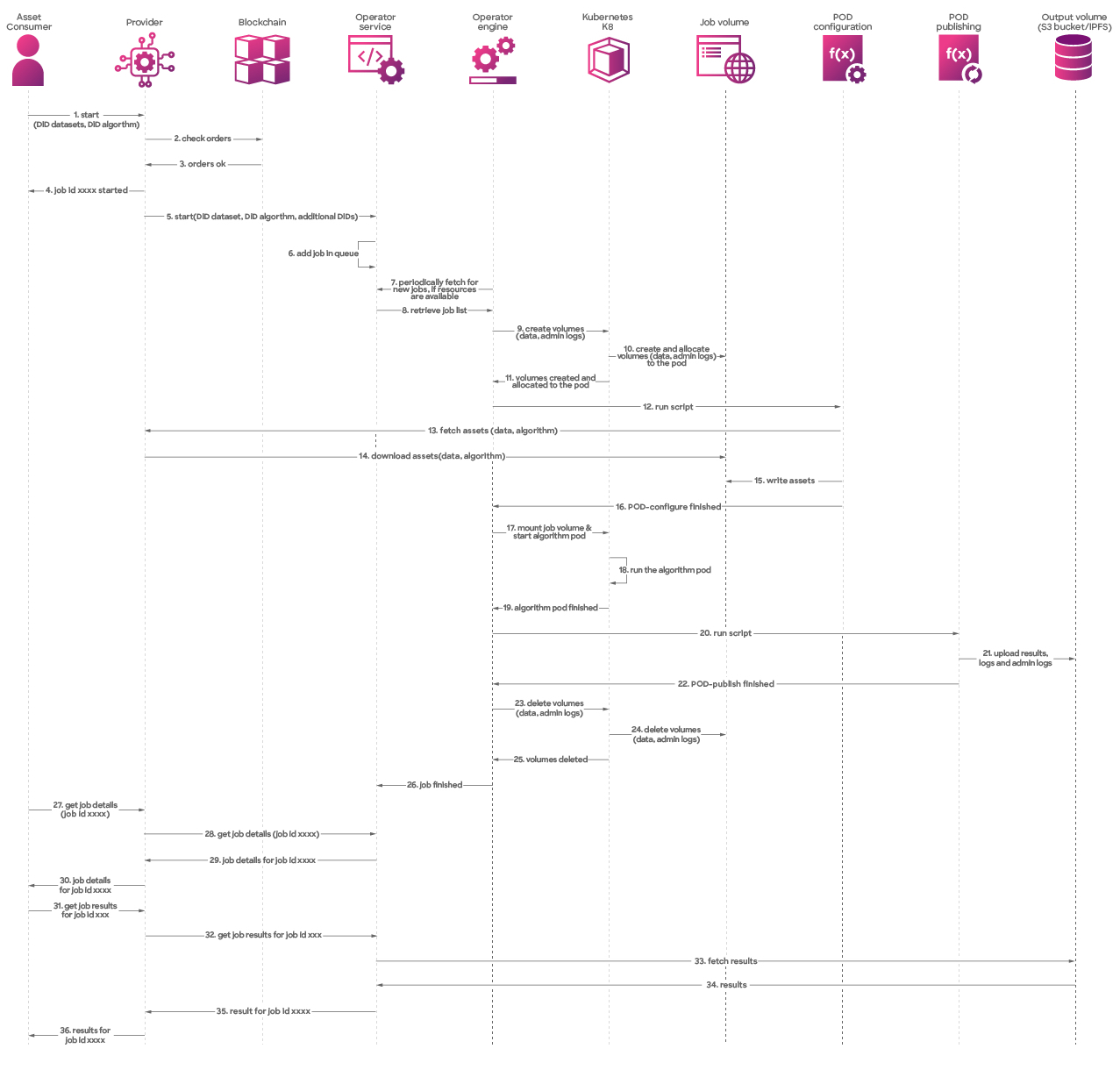
Compute detailed flow diagram
Below, we'll outline each step in detail 📝
Starting a C2D Job
- The consumer selects a preferred environment from the provider's list and initiates a compute-to-data job by choosing a dataset-algorithm pair.
- The provider checks the orders on the blockchain.
- If the orders for dataset, algorithm and compute environment fees are valid, the provider can start the compute flow.
- The provider informs the consumer of the job's id successful creation.
- With the job ID and confirmation of the orders, the provider starts the job by calling the operator service.
- The operator service adds the new job in its local jobs queue.
- It's the operator engine's responsibility to periodically check the operator service for the list of pending jobs. If there are available resources for a new job, the operator engine requests the job list from the operator service to decide whether to initiate a new job.
- The operator service provides the list of jobs, and the operator engine is then prepared to start a new job.
Creating the K8 Cluster and Allocating Job Volumes
- As a new job begins, volumes are created on the Kubernetes cluster, a task handled by the operator engine.
- The cluster creates and allocates volumes for the job using the job volumes.
- The volumes are created and allocated to the pod.
- After volume creation and allocation, the operator engine starts "pod-configuration" as a new pod in the cluster.
Loading Datasets and Algorithms
- Pod-configuration requests the necessary dataset(s) and algorithm from their respective providers.
- The files are downloaded by the pod configuration via the provider.
- The pod configuration writes the datasets in the job volume.
- The pod configuration informs the operator engine that it's ready to start the job.
Running the Algorithm on Dataset(s)
- The operator engine launches the algorithm pod on the Kubernetes cluster, with volume containing dataset(s) and algorithm mounted.
- Kubernetes runs the algorithm pod.
- The Operator engine monitors the algorithm, stopping it if it exceeds the specified time limit based on the chosen environment.
- Now that the results are available, the operator engine starts "pod-publishing".
- The pod publishing uploads the results, logs, and admin logs to the output volume.
- Upon successful upload, the operator engine receives notification from the pod publishing, allowing it to clean up the job volumes.
Cleaning Up Volumes and Allocated Space
- The operator engine deletes the K8 volumes.
- The Kubernetes cluster removes all used volumes.
- Once volumes are deleted, the operator engine finalizes the job.
- The operator engine informs the operator service that the job is completed, and the results are now accessible.
Retrieving Job Details
- The consumer retrieves job details by calling the provider's
get job details. - The provider communicates with the operator service to fetch job details.
- The operator service returns the job details to the provider.
- With the job details, the provider can share them with the dataset consumer.
Retrieving Job Results
- Equipped with job details, the dataset consumer can retrieve the results from the recently executed job.
- The provider engages the operator engine to access the job results.
- As the operator service lacks access to this information, it uses the output volume to fetch the results.
- The output volume provides the stored job results to the operator service.
- The operator service shares the results with the provider.
- The provider then delivers the results to the dataset consumer.