# Downloading compute results
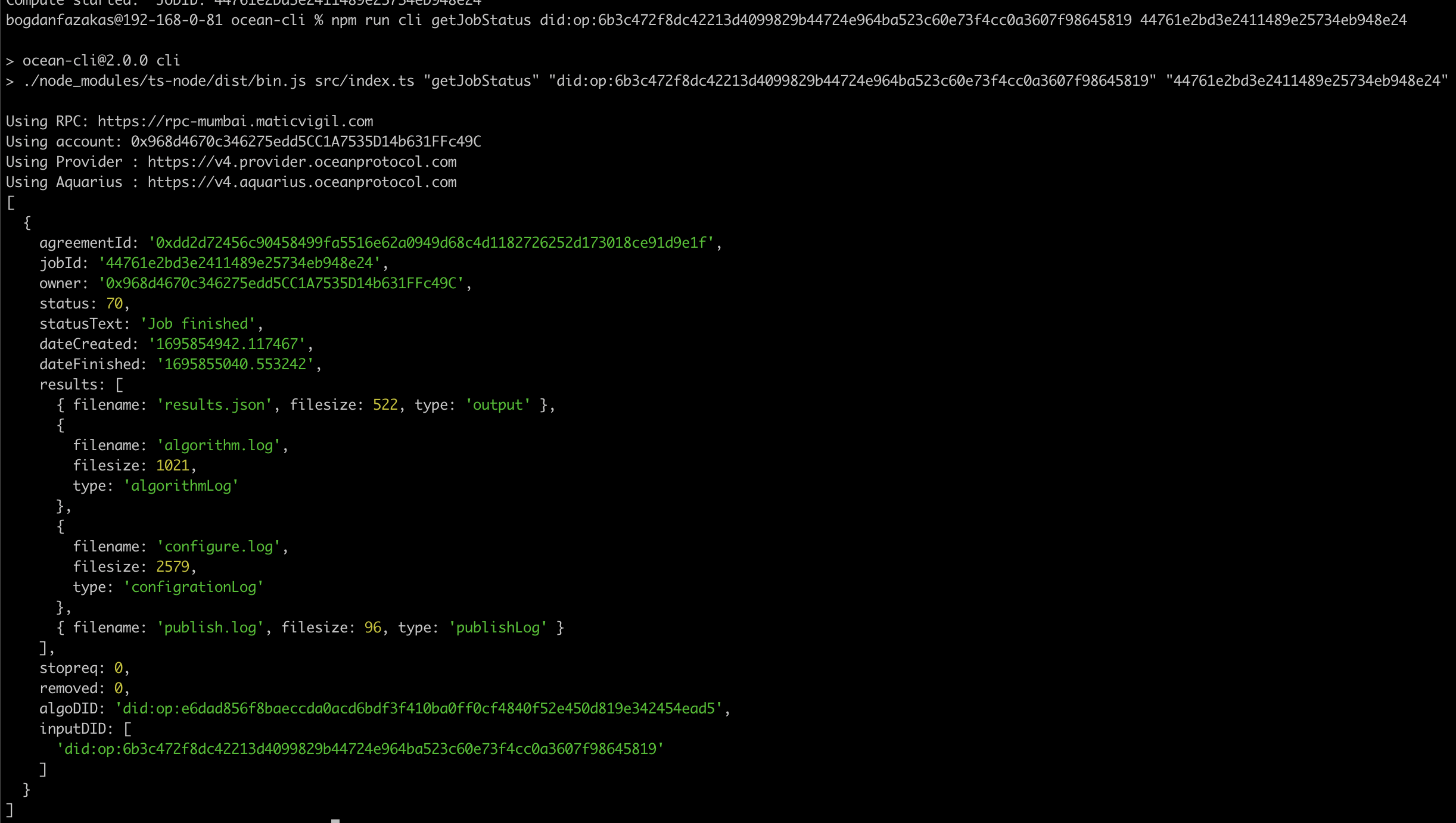
To retrieve the compute results, we'll employ two distinct methods. Initially, we'll use the getJobStatus method, where we'll wait for or periodically check the status until it indicates that the job is finished. Subsequently, we'll utilize the method to obtain the actual results.
For the first method, you'll need both the dataset DID and the compute job DID. You can execute the following command:
```bash
npm run cli getJobStatus 'DATASET_DID' 'JOB_ID'
```
This command will enable you to monitor the status of the job and ensure it has completed successfully.
getJobStatus
For the second method, the dataset DID is no longer required. Instead, you'll need to specify the job ID, the index of the result you wish to download from the available results for that job, and the destination folder where you want to save the downloaded content. The corresponding command is as follows:
```bash
npm run cli downloadJobResults 'JOB_ID' 'RESULT_INDEX' 'DESTINATION_FOLDER'
```
downloadJobResults